

摘要:为更加快捷且不破坏样品地对选后烟叶的化学成分(烟碱、总糖、还原糖、总氮、钾、氯)值进行检测,有效地组织打叶复烤均值化加工,应用选后烟叶中烟碱含量变化与其对应的近红外光谱变化之间存在相关关系,采用漫反射方式获取校正样品集近红外漫反射光谱,选择微分、平滑、PLS等方法进行数据预处理,把校正样品集近红外光谱与其相应的主要化学成分含量或指标值进行关联,建立校正模型,使用验证样品集对校正模型有效性进行验证。通过对检测结果进行分析,该建模流程是可行的,为选后烟叶烟碱值的检测提供了一种更加快捷且无损的方法。
关键词:选后烟叶、烟碱、手持式、近红外、建模
烟草是我国的重要经济作物之一,由于受品种、栽培技术、土壤、气候、收购眼光等因素影响,使同一产地、同一等级的烟叶在不同收购时段内在品质上存在差异。打叶复烤均值化加工就是通过一定形式的参配,使打叶复烤后的烟叶形成一个内在质量稳定、理化指标均匀的成品片烟或配方模块。在烟草的众多质量评价指标中烟碱的含量,直接影响烟草制品评吸质量,是配方设计的基础控制因素。早在2015 年中国烟草总公司就通过文件明确要求要将成品片烟的烟碱变异系数控制到 5%以内。卷烟加工企业调入打叶复烤企业加工的烟叶一般要经过原烟入库、烟叶分选、配方打叶等流程,而对选后烟叶烟碱含量的情况掌握是均质化加工配方设计的关键环节。打叶复烤企业对烟叶中烟碱的检测一般是使用连续流动分析法,近年来随着化学计量学与计算机技术的飞速发展,实验室近红外检测烟叶中烟碱的含量得到了广泛应用。但是不论是连续流动分析法还是实验室近红外检测均需对样品进行粉碎,且数据获得存在一定的滞后性。
本文通过对一种手持式近红外光谱分析仪建模的研究,提供了一种不破坏样品且更加快捷的烟叶中烟碱的检测方法,有助于打叶复烤企业灵活快捷地组织均质化加工工作。
1 材料与方法
1.1材料和仪器
1.1.1 材料
云南初烤烟叶(选后烟叶)总计350个作为常规化学指标模型建模样本,所有样本产地包括云南昆明、曲靖、文山、丽江、临沧、玉溪产区,主要等级包括B1F、B2F、B3F、C1F、C2F、C3F、C4F、X2F、X4F
1.1.2仪器
德国Carl Zeiss公司生产的AURA手持式近红外光谱仪(以下简称AURA)(如图1)。

图1 AURA手持式近红外光谱仪
美国ThermoFisher公司生产的 Antaris II 傅里叶变换近红外光谱仪(以下简称Thermo)(如图2),此仪器已经完成建模,且使用稳定。

图2 Antaris II 傅里叶变换近红外光谱仪
2 样品准备
根据石林复烤厂烤季生产原烟情况,选取不同产地、等级烟叶样品350个,具体信息如下图表1:
图表1 取样表:

每个样品取6-8片烟叶,放入自封袋中,后续进行手持式近红外光谱仪建模扫样,对样品进行统一编号。编号由取样样品编号、产地、等级组成。如:“ 001#-昆明-C4F”,代表001号样品,产地为“昆明”,等级为“C4F”。
3 光谱采集
建模光谱扫描采用手持式(AURA)近红外光谱仪,序列号为131517。手持式近红外光谱仪有效光斑直径为18mm,采用与烟叶表面直接接触的扫描方式。

图表2 接触式扫描
如下图表3所示,将6片烟叶叠放在一起,用手持式近红外光谱仪(六点扫描)工作流,先扫描3次,分别是叶尖,叶腰,叶基(对应图表的点1、点2、点3)各扫描一次,得到3条光谱;之后将最下面的三片烟叶抽出放置最上面,再次进行叶尖,叶腰,叶基三次扫描。扫描完毕后,每个烟叶样本对应6条光谱。保持样本名称与取样的名称一一对应。6次扫描近红外的外界环境保持相对稳定。


图表3常规化学模型检测点
由于外界环境的变化会引起光谱发生变化,为了消除这些影响,在每个样品测量之前,仪器将进行背景校正,防止光谱发生偏移,且当外部环境温度变化超过2℃时,仪器会自动进行背景的校正。
4 模型建立
4.1 光谱预处理
手持式近红外的采集光谱中除含有待测样品的原始的化学信息外,还包含其他外在的干扰信息和噪声,这些信息噪声将导致测得的化学信息数值与真实值之间存在一定的差异。为了提高信噪比尽可能消除误差,应该保持实验的环境因素尽量稳定一致,除了环境因素之外还需要各种数据处理方法来减少甚至去除各种干扰光谱信息的影响因素。为下一步的数据处理奠定基础。较常用的光谱数据处理方法有均值中心化(mean centering),归一化处理(normalization),平滑,求导,标准正态变量变换(SNV),多元散射校正(MSC),傅立叶变化和其他一些新的方法,化学指标模型建立的过程中,会用到一阶导数的预处理方法。
Ø 导数
导数(微分)可以消除样品光谱的基线漂移、增强谱带的特征信息并克服谱带重叠,是最为常用的光谱数据预处理方法。一阶导数可以去除同波长无关的基线漂移;二阶导数可以去除同波长线性相关的基线漂移。在原烟的数据采集中,导数计算可以减少基线偏移、漂移和背景干扰造成的数据偏差。
4.2异常样本剔除
异常样本在近红外整个模型的构建过程中会对模型存在很大的影响,不仅会会误导近红外变量的选择,而且这些奇异值还会给模型的参数估计带来偏离,降低模型的精度与稳健性;在实际近红外构建模型的过程中,有很多情况会引起近红外样本的异常,大体上分为近红外光谱的异常与近红外化学值的异常;按照引起异常样本的原因又可具体的分为如下几种情形:
①环境引起的异常光谱,比如近红外仪器背影变化产生的影响或者扫到了非信号物质,检测条件的变化,如样本的温度,湿度;
②仪器自身的不稳定引起的异常光谱。比如仪器的检测器两端做的比较粗糙所仪器的问题;近红外随着长时间的使用仪器的老化,以及更换近红外仪器的零部件带来的光谱差异;
③被检测物质自身所引起的异常光谱;这类异常光谱比较特殊,这是近红外应用模型维护所必须需要考虑到的问题,由于地域以及年度之间的差异导致了未来的光谱与模型里面产生的光谱不一致;
④由于工艺参数的改变仪器的异常光谱,近红外光谱受外界环境影响比较大,如改变某些工艺参数,导致近红外仪器检测条件发生变化,比如真空回潮等参数会改变烟叶物质中所含有的水分;这个时候外界的湿度因素就会发生变化,产生异常光谱;
⑤基础数据产生的异常样本,当基础数据操作失误,或者样本混淆的时候,化学值与样本所对应的近红外光谱不一致所产生的异常样本;
手持式近红外异常光谱的常用剔除方法是半数重采样法和蒙特卡洛偏最小二乘交叉检验法。
Ø 半数重采样法
基于对原始光谱的随机半数重采样统计出现奇异长度的样本。从原始光谱矩阵中随机选择部分(一般选择总样本数的一半)样本作为采样子集,计算每个采样子集矩阵的均值和方差,再根据均值和方差计算采样子集中每个样本的向量长度(向量长度计算公式与数据标准化公式相同)。对光谱数据进行多次随机采样,并记录每次采样后计算的向量长度。对样本的向量长度进行排序,距离最大的一定概率(如 5%或 10%)的样本得分为 1,其余为 0。最后对各样本的总得分进行统计,得分最高的部分样本就为奇异样本。
Ø 蒙特卡洛偏最小二乘交叉检验
基于蒙特卡罗交叉验证(MCCV)的一类奇异样本识别方法。利用 MCCV 随机划分校校正集与预测集,如果奇异样本在校正集中,整个模型的质量将受到影响;相反,如果奇异样本在预测集中,仅此样本的预测结果受到影响。尽管这种情况对预测结果都有影响,但效果明显不同。本文就利用奇异样本出现在校正集或预测集时模型预测误差的差异,通过 MCCV 及统计分析来进行奇异样本的识别。根据预测集中奇异样本的预测残差会明显大于正常样本的预测残差也提出了一种基于MCCV的奇异样本识别方法。基于 MCCV的奇异样本识别方法充分利用统计学的性质,能够在一定程度上降低由掩蔽效应带来的风险,检出光谱阵和性质阵方向的奇异点,有望在奇异样本检测中得到更广泛的应用。
4.3 波长变量选择
在校正模型的建立过程中,选取参与校正的样本和光谱信息变量对建立稳定的模型时十分必要的。光谱信息变量选择是从原始变量中挑选出一些有代表性的特征变量,代替原始变量进行数据分析和处理。在烟草无损检测试验中,近红外光谱仪每次可获取大量的光谱数据,应着不同原始光谱数据对待测烟叶样品的品质信息的贡献率不能完全相同,有些光谱信息变量反映的信息较为丰富,有些光谱信息变量反映的信息量较少,甚至与待测烟叶样品品质成分含量无关。如果将近红外光谱仪所获取的光谱数据都用于建立模型,则建模计算时间很长,计算量也很大,建立的近红外光谱预测模型复杂,模型的稳定性差。研究发现,通过特定的光谱信息变量筛选方法对原始光谱信息变量进行优选,其作用是可减少模型的建立时间,简化建模过程,最重要的是可以剔除无信息变量或非线性变量,最终可以建立跟随性强、预测能力好的近红外定量校正模型。
手持式近红外常用的波长选择方法是CARS(竞争性自适应加权取样法),具体的计算过程如下:
竞争性自适应权重取样(competitive adaptive reweighted sampling, CARS)竞争性自适应加权取样(CARS)是一种基于回归系数进行波长点选择的方法。该方法模仿达尔文进化论中的“适者生存”原则,将每个波长看作一个个体,对波长实施逐步淘汰。利用回归系数绝对值的大小作为衡量波长重要性的指标,同时,引入了指数衰减函数来控制波长的保留率。每次通过自适应重加权采样技术筛选出 PLS 模型中回归系数绝对值大的波长点,去掉权重小的波长点,利用交差验证选出模型交叉验证均方根误差(root mean square error of crossvalidation, RMSECV)值最低的子集,可有效选择与目标值相关的最优波长组合。CARS-Monte-Carlo-sampling算法采用蒙特卡罗采样法采样N次,每次从样品集中随机抽取 80%的样品作为校正集,利用抽取的光谱矩阵,和浓度矩阵,分别建立PLS模型,采用指数衰减函数EDF强行去除回归系数值相对较小的波长点,第i次采样时,波长点的保留率r=e-bt,第一采样时,所有的m个变量都被用于建模,故第N次采样时仅两个波长被使用,通过N 次采样时筛选出 PLS 模型中回归系数绝对值大的波长点,用每次产生的新变量子集建立PLS回归模型,计算每个模型的交互验证均方差 RMSECV,选择 RMSECV 值最小的变量子集,即为最优变量子集。
4.4 建模方法
定量分析是对被研究对象所含成分的数量关系或所具备性质件的数量关系进行量化的分析过程。采用无损检测技术获取烟叶的化学成分信息时,通常只能获取与待测样品化学成分相关的间接信息(如光谱信息),如果要进一步了解待测样品的品质信息(如烟碱、总糖、总氮等),则需要将无损检测方法所获取的待测样品信号特征与常规方法(如流动分析法或者其他化学方法)获取的信息建立相应的定量校正分析模型。
偏最小二乘(partial least squares, PLS)也是一种基于因子分析的多变量校正方法,在主成分回归中,只对光谱矩阵X进行分解,消去了自变量光谱阵X中的噪声信息,而因变量浓度阵Y也会含有不相关信息,因此因变量浓度阵Y也应同样处理。与PCR不同的是,在PLS中,自变量光谱阵X和因变量浓度阵Y的分解应该同时进行,应该是将光谱阵X信息引入到浓度阵Y的分解过程中,在每计算光谱阵一个新的主成分之前,交换光谱阵X与浓度阵Y的得分,从而使自变量主成分直接与被分析组分含量关联。20世纪80年代开始PLS就应用于化学分析研究,现在化学计量学中多变量校正方法中最受推崇的之一就是PLS,广泛应用在化学分析测量和相关的研究中。
4.5 模型评价
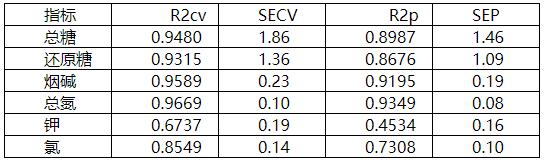
通常校正集和验证集中都会有相关系数(R)、校正集中有校正标准偏差(SEC/RMSEC)、验证集中有预测标准偏差(SEP/RMSEP)等。
(1) 相关系数
两个定量校正结果相关程度的一个统计量是用决定系数来描述的,它主要是用来判断定量校正模型与待测组分的线性关系的好坏
(2) 校正标准偏差和预测标准偏差
建立近红外光谱定量校正模型时,通常是要将样品分为校正集和预测集两个部分,校正集样本是用来建立定量校正模型,预测集是用来对模型进行验证的,通过比较真实值与预测值的差异,来判断模型预测能力的好坏。SEC和SEP是计算模型得出的真实值与其预测值之间的误差平方和的均方根值。
在校正模型中,采用留一交互验证法来建立定量校正模型。留一交互(叉)验证法就是:每次从烟叶校正样本集中取出一个烟叶样本,然后用余下的烟叶样本来建立校正模型,用建好的校正模型来预测之前取出的这个烟叶样本,直到烟叶校正样本集中每个烟叶样本都被取出过一次。
对同一批次样本,SEC和SEP值越小说明模型的精度越高,两者值越接近说明模型稳定性越好。
4.6 手持式模型分析
(1) 光谱预处理
通过对建模光谱的分析,由于手持式近红外采取了直接紧贴烟叶表面的扫描方式,且外部环节保持相对稳定,采集的光谱复杂程度并不高,只需要利用一介导数的预处理方法来提高模型的精度即可;
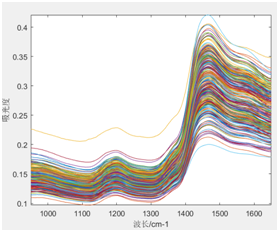
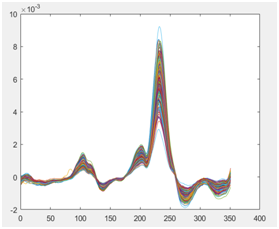
图表4 原始光谱 图表5 光谱一阶导数
(2) 异常样本剔除
采用蒙特卡洛交叉验证剔除化学值异常的样本,对下图比较分散的样本进行剔除,由于是纵坐标比较分散的样本点。
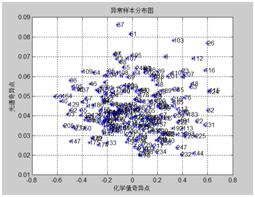
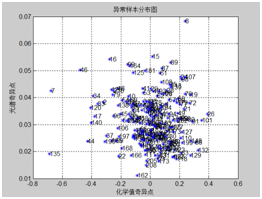
图表6 烟碱异常统计 图表7 氯异常统计
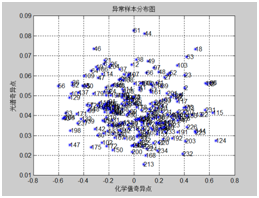
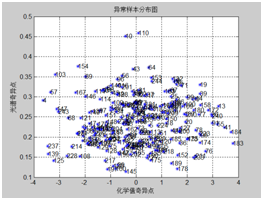
图表8 总糖异常统计 图表9 还原糖异常统计
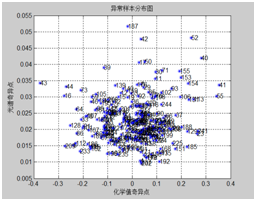
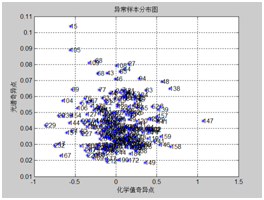
图表10总氮异常统计 图表11 钾异常统计
(3)波长变量选择
建模发现采用竞争性自适应权重取样 (CARS)方法选择的波长建立的模型效果最佳,成分数选择13
(4)模型建立
采用偏最小二乘法建立的回归模型效果最佳,下图分别是6个指标的PLS模型预测值与真实值对比图和真实值绝对误差图。从图中可以看出,所有模型都集中的回归直线附近,误差也近似正态分布,说明建立的模型效果较好。
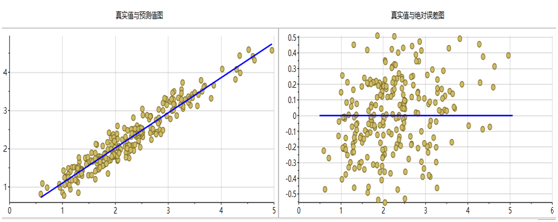
图表12 烟碱模型
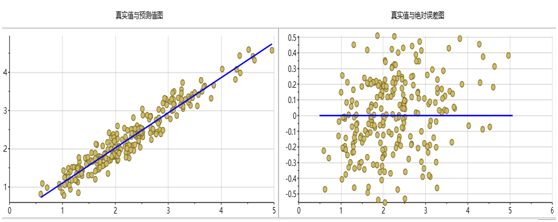
图表13 总糖模型
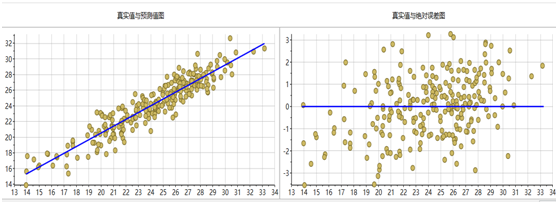
图表14 还原糖模型
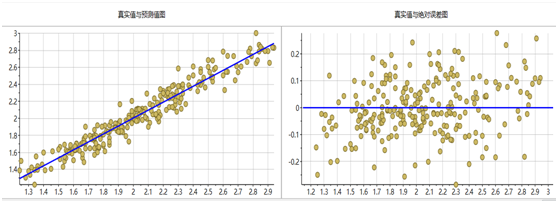
图表15 总氮模型
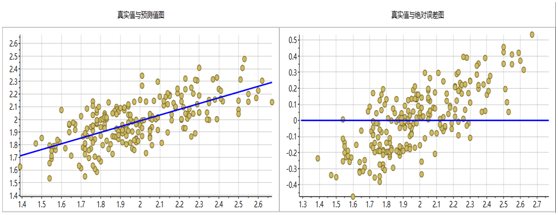
图表16 钾模型
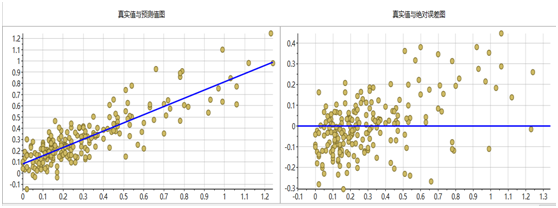
图表17 氯模型
(5)模型评价
图表18 模型评价结果
5 模型外部验证
烟碱指标
图表19 烟碱外部验证结果
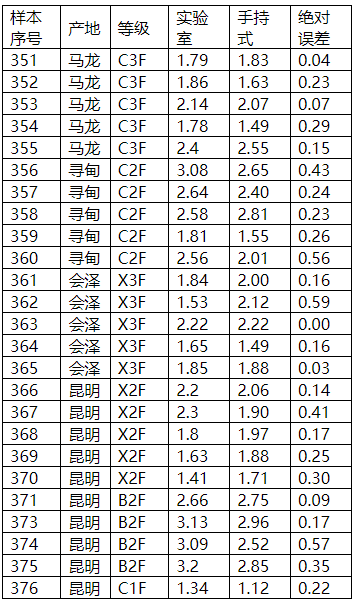
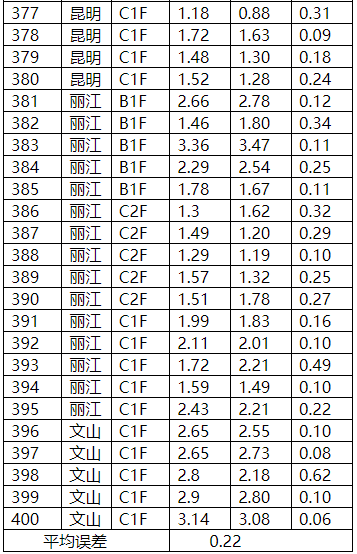

图表20 烟碱外部验证比对图
总糖指标
图表21 总糖外部验证结果
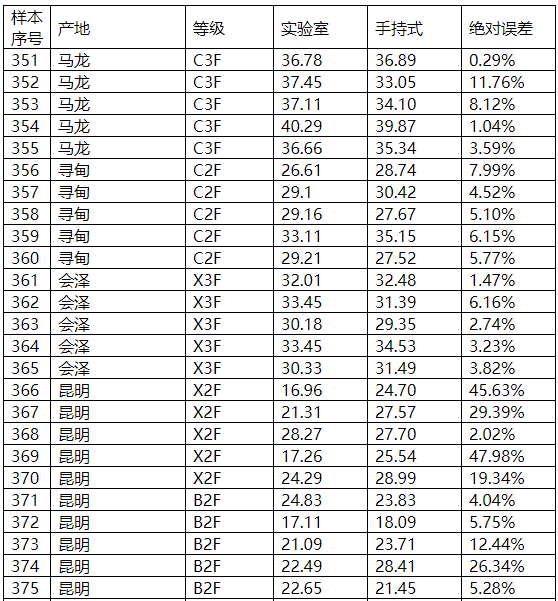

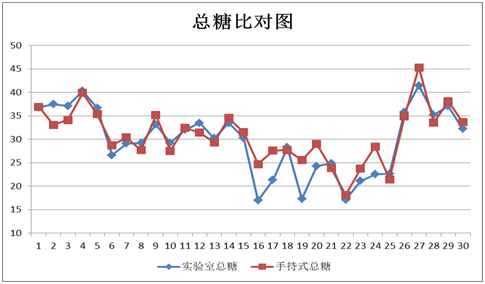
图表22 总糖外部验证比对图
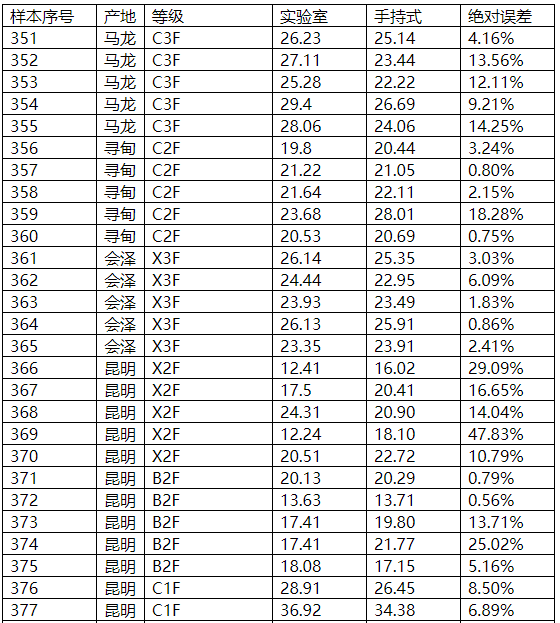
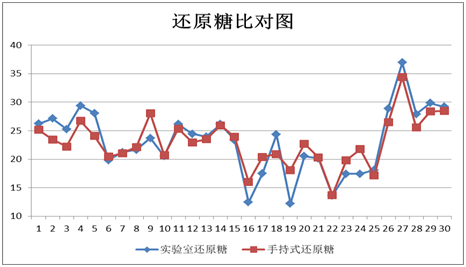
还原糖指标
图表23 还原糖外部验证结果

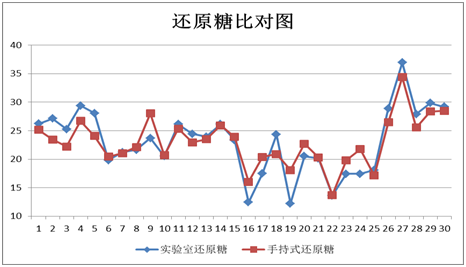
图表24 还原糖外部验证比对图
总氮指标
图表25 总氮外部验证结果
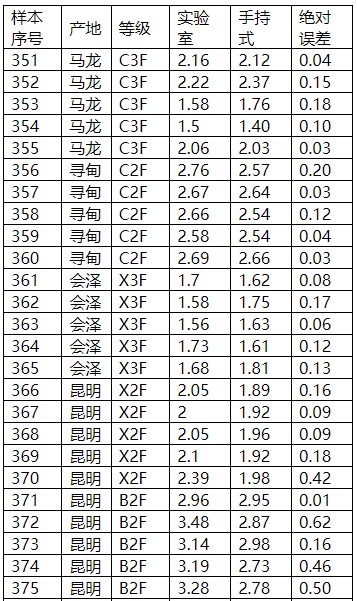
图表26 总氮外部验证比对图
钾指标
图表27 钾外部验证结果
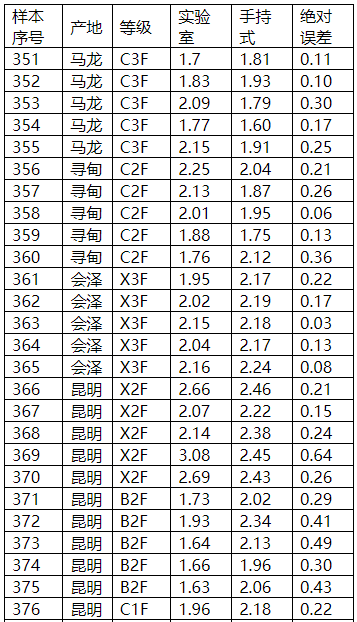
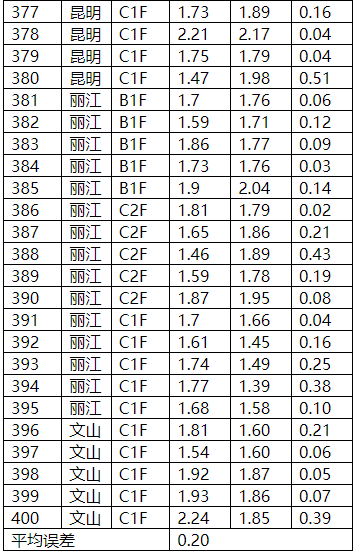
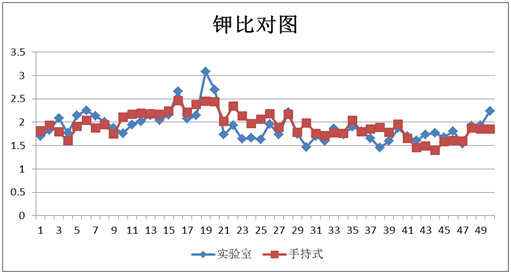
图表28 钾外部验证比对图
氯指标
图表29 氯外部验证结果
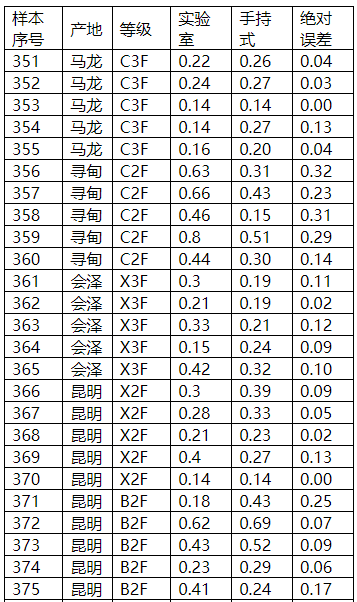
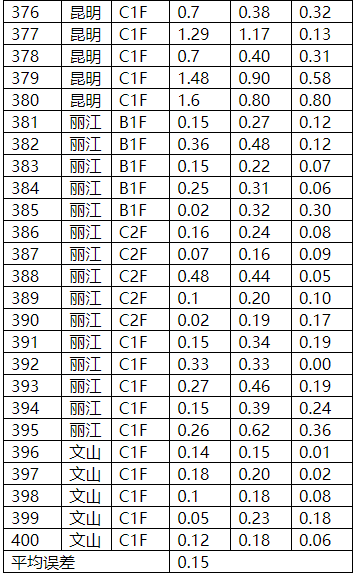
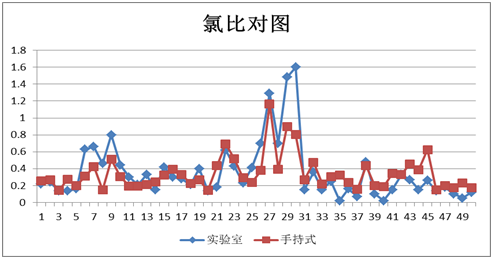
图表30 氯外部验证比对图
验证结论
图表31 50个验证样本验证结果

对上述表格数据进行分析,手持式近红外对原烟相关化学指标的检测结果基本都达到了实际使用的精度需求。模型内部建模样本化学值梯度基本能够覆盖常规检测样本的化学值范围,模型对不同等级产地或者时间梯度的原烟具有有稳定的预测能力,且对绝大部分样本的预测误差落在一定的范围内,整体误差呈正态分布;
建模样本分析
此次模型中包含350个建模样本,主要包括云南昆明、曲靖、文山、丽江、临沧、玉溪主要产区,建模样本基本覆盖了云南烟叶复烤有限责任公司石林复烤厂烤季原烟的所有产区。其中,上部烟样本数量为79,中部烟数量为184,下部烟数量为87,建模样本在部位分布上基本满足模型建立的需求,模型对不同产地不同等级的原烟都具有较好的预测能力。
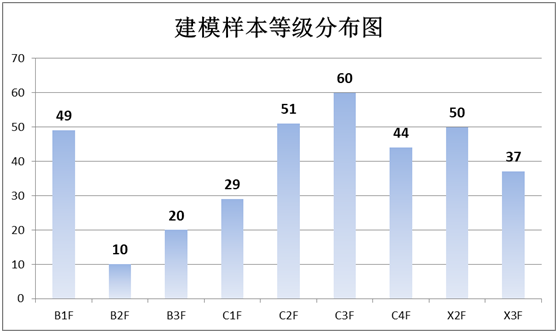
图表32 产地分布图
对建模样本基础数据分析,烟碱、总糖、还原糖、总氮等指标的建模集化学值分布基本都呈正态分布,能够满足模型建立的要求。
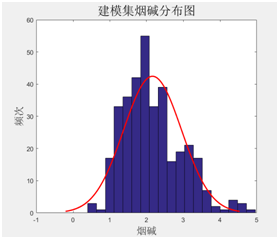
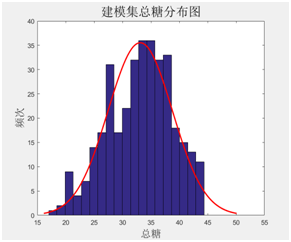
图表33建模集烟碱分布图 图表34 建模集总糖分布图
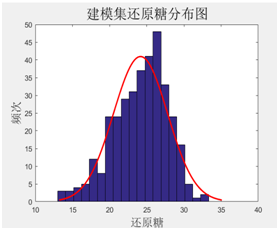
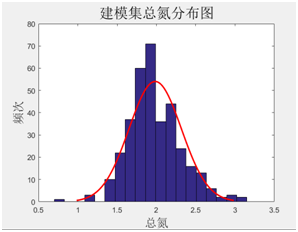
图表35 建模集还原糖分布图 图表36 建模集总氮分布图
6 结论
综上所述,基于350个样品所建立的6种常规化学成分的预测模型,其相关系数及偏差均符合项目要求。其中,烟碱预测模型的决定系数高达0.96,平均绝对偏差值为0.22。建立的预测模型可应用于烟叶卸车、入库、挑选等不同环节的原烟化学信息检测,其检测数据可为原料烟叶的化学成分波动、质量分析等提供可靠的数据,进行一次调控,为均质化配方打叶提供数据支撑。
注:本文来源于网络,如有侵权请联系删除
